|
Задачата може да се раздели на 2 части – компресиране
на растерното изображение на дадена цифра, и компресиране на информацията за повтарящите
се цифри. В моето решение компресирам цялото число (разглеждано като низ), но не
твърдя, че това е оптималния вариант.
Очевидно двете подзадачи изискват различен подход, т.е. различен
алгоритъм за компресиране.
Тъй като целта е да се постигне максимална компресия във всички
тестови примери, добър подход би бил да се реализират няколко компресиращи алгоритъма,
и във всеки отделен случай да се избира най-оптималния. Но това изисква доста време
за рисърч и имплементиране, така че съм реализирал само по 1 алгоритъм за числото
и растера. J
Компресиране на числото
В началото на NUM.COD записвам
компресираното число. Използвам речниково кодиране – LZSS ([1]). Реализацията си я написах сам, тъй като самият алгоритъм е не е труден.
Очевидно това не е най-добрия вариант за малки числа, но не остана време за частни
случаи.
Самата реализация е оптимизирана, доколкото е възможно: Цифрите
се кодират в 4 бита. Позициите и дължините на съвпадащи низове би трябвало да се
кодират в 10 бита, тъй като максималната допустима стойност за тях е 1000. Това
обаче си е живо разхищение, затова при кодирането/декодирането на цифрата на позиция
p (в случай на намерен съвпадащ низ) се прави следната оптимизация:
-
позицията се кодира в толкова битове, колкото са достатъчни
за числото p
-
дължината се кодира в толкова битове, колкото са достатъчни за min(p, len-p).
При декодирането обаче е необходимо да се знае дължината на цялото число (заради
горната оптимизация), поради което в началото се записва броя на цифрите (в 10 бита).
Това също би могло да се оптимизира.
След това във NUM.COD се записват
компресираните растери на различните цифри от числото, в реда, в който се срещат
в него.
Компресиране на растера
За компресиране на растера използвам стандарта CCITT T.6 за компресиране на
факс изображения ([2]). Разглеждат се позициите на всеки ред, при които бялото се
сменя с черно, или обратното. Изображението се сканира ред по ред, и всеки ред се
описва със разликите на тези позиции спрямо предишния.
Накратко ще опиша как се кодира даден ред. По-подробно описание може да се намери
на линка долу ([2]).
Едновременно се сканират текущия ред и предишния. Разглеждат се само позициите
на смята на цвета. Нека p1 е позиция в предния ред, а p2 – в текущия. В зависимост
от тези позиции, се кодират следните режими:
| Mode |
Описание
|
Кодиране (битове)
|
Action
|
|
V(0)
|
Ако p2 = p1
|
1
|
p1++, p2++
|
|
VR(1)
|
Ако p2 = p1 + 1
|
011
|
p1++, p2++
|
|
VR(2)
|
Ако p2 = p1 + 2
|
000011
|
p1++, p2++
|
|
VR(3)
|
Ако p2 = p1 + 3
|
0000011
|
p1++, p2++
|
|
VL(1)
|
Ако p2 = p1 – 1
|
010
|
p1++, p2++
|
|
VL(2)
|
Ако p2 = p1 – 2
|
000010
|
p1++, p2++
|
|
VL(3)
|
Ако p2 = p1 – 3
|
0000010
|
p1++, p2++
|
|
Pass
|
Ако p1 + 3 < p2
|
0001
|
p1++
|
|
H
|
Ако p2 + 3 < p1
|
001 + p2 (5 бита)
|
p2++
|
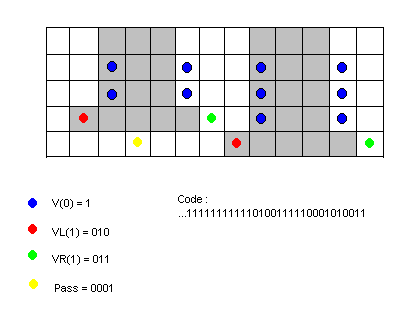
В моята реализация съм се постарал да избегна кодиране за край или начало на ред.
Когато при декодиране се преминат всички позиции от предния ред, но въпреки това
следващия код е отново V-режим или Pass, oчевидно трябва да се премине на следващия
ред. Това не е вярно в случая на H-режим, поради което тогава добавям V(0) за означаване
на края на реда.
Освен това за разделител между цифрите използвам код 000000.
Гореописаният алгоритъм е без загуба. Като малка
оптимизация премахвам цели редове отгоре и отдолу (на всяка стъпка избирам този
с повече черни пиксели – опс, грешка!), докато не могат да се махнат повече редове
(поради ограничението от максимална загуба 16 пиксела). По този начин намалявам
редовете за кодиране, което не е много съществено. Истинското решение е да се премахват
не редовете с най-много черни пиксели, а тези, които се компресират с повече битове,
и евентуално да се опитат някакви изглаждания на символа, което обаче е съвсем различна
задача.
Възможни оптимизации:
-
адаптивни кодове за режимите на T.6
-
компресиране по колони, не по редове
-
по-сложен lossy алгоритъм
-
други алгоритми за компресиране – например чрез prediction (подобно на JBIG).
Детайли по реализацията
Малка тръпка в реализирането на алгоритмите беше
работата с числа с променлив брой битове. Класът CBitData се справя с този проблем. (Компресирането на растера използва bit-string
вместо този клас, защото беше реализирано малко по-рано.) J
Самата реализация е в класа CNumberCompressor.
URLs
[1] http://www.rasip.fer.hr/research/compress/algorithms/fund/lz/lzss.html
[2] http://www.rasip.fer.hr/research/compress/algorithms/adv/fakscomp/index.html |